

Oppgave 3
En (europeisk) rulett har 37 felter, som er nummerert 0 og 1 til 36. Feltet 0 har fargen grønn, 18 er røde og 18 er sorte. For mer informasjon, se http://no.wikipedia.org/wiki/Rulett. Croupieren (spillelederen) spinner hjulet og ruller en liten ball langs hjulet i motsatt retning. Hjulet er balansert slik at det er like sannsynlig å lande på alle feltene. Spillerne kan spille på alle kombinasjoner av tall og farger.
1. Hva er sannsynlighetene for å falle i hvert av feltene?
1/37
2. En spiller som spiller på rødt, vinner hvis ballen lander på et rødt felt. Hva er sannsynligheten for dette?
18/37
3. Spillekasinoet har bestemt at dersom kulene lander på feltet 0 (”huset vinner”), går innsatsen til spillerne til spillekasinoet. Hva er sannsynligheten for at spillekasinoet skal få innsatsen til en spiller?
1/37 P for at kulen lander på 0
19/37 for å tape gitt at sats på 0 ikke er mulig
4. Du går i spillekasinoet en kveld og bestemmer deg for å spille 20 ganger. Hver gang satser du 1000 kroner og hele tiden satser du på rødt. Hver gang kulen lander på sort eller på 0, går pengene dine til spillekasinoet, og hver gang det blir rødt, får du igjen det dobbelte av det du satset. Kan du forvente å vinne på dette spillet? Hvis ikke, hvor mye vil du i så fall måtte forvente å tape?
E(r) = 18/37 * 20 = 9.73
E(ir) = 19/37 * 20 = 10.27
Vi ser at andelen spill vi kan forvente å vinne blir mindre etterhvert som vi spiller flere spill. Om vi spiller 20 ganger kan vi forvente å vinne ~48.65% av gangene, altså 9.73 eller ~10 spill. Likeså forventer vi å tape ~51.35% av gangene, altså 10.27 eller ~ 10 spill. Ettersom vi bare kan spille “hele spill”, kan vi si at vi forventer å gå i null, men at sannsynligheten for at vi taper er større enn at vi vinner.
5. En annen spiller har observert at det har kommet rødt seks ganger etter hverandre. Han synes dette er mistenkelig og konkluderer med at ”rødt er i skuddet”, og vil fra da av satse bare på rødt. Hvis spillet er «rettferdig» i den forstand at sannsynligheten er som vi antok i pkt. 2, hva er da sannsynligheten for at kulen skal falle på rødt 6 ganger etter hverandre?
P(6rød) = (18/37)^6 ~= 0.013 = 1.3%
6. Spilleren mener at sannsynligheten for å falle på rødt kanskje kan være så høy som 0.6, siden kulen faller så ofte på rødt. Hva er sannsynligheten for at det skal komme rødt seks ganger hvis sannsynligheten er 0.6?
P(6rød) = (0.6)^6 ~= 0.047 = 4.7%
7. Spilleren vil gå til spillelederen og si at spillet ikke er rettferdig. Hva vil du si til denne spilleren? For å begrunne svaret ditt kan du tenke deg at spillelederen i løpet av en kveld rekker å spille 1000 sekvenser à 6 spill. Hvor mange av disse sekvensene kan vi forvente vil gi 6 røde på rad, når spillet er «rettferdig»?
P(6rød) ~= 0.013.
E(x) = 0.013*1000 = 13 sekvenser
Oppgave 4
En meteorolog som er ansatt på Værnes har fått gjentatte klager fordi han ikke klarer å treffe med værmeldingene sine. For å vurdere kvaliteten på det utførte arbeidet har sjefen hans laget en tabell med observerte frekvenser for hva meteorologen meldte og det det været som faktisk ble observert.
 Bruk sannsynlighetsregnereglene vi har lært til å svare på følgende spørsmål:
Bruk sannsynlighetsregnereglene vi har lært til å svare på følgende spørsmål:
1. Hva er sannsynligheten for sol?
Addisjonsregelen.
P(S) = 0.3 + 0.05 + 0.05 = 0.4 = 40%
2. Hva er sannsynligheten for at meteorologen tar feil?
Komplementsetningen.
P(F) = P(iR) = 1 – P(R) = 1 – (0.3+0.2+0.2) = 1 – (0.7) = 0.3 = 30%
3. Hva er sannsynligheten for at for det kommer regn når meteorologen sier det blir sol?
P(R|OS) = 0.1 / 0.44 ~= 0.23 = 23%
Oppgave 5
Vi er interessert i å se på sammenhengen mellom en test og en sykdom for å undersøke testens evne til å skille mellom syke og friske. Vi ser på et utvalg av 50.000 personer som har blitt testet for en bestemt sykdom. Av disse har 100 sykdommen. Av de 100 som har sykdommen er det 95 som får positivt testresultat. Av de som er friske er det 48902 personer som får negativt testresultat.
1. Sett opp en tabell som viser antall syke/friske med positiv/negativ test.
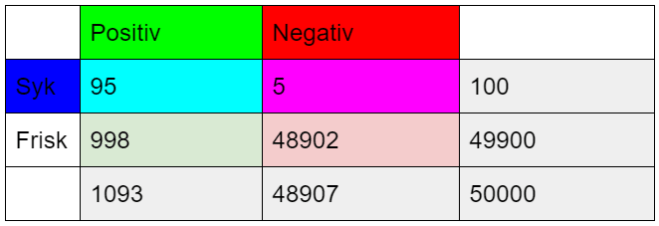
2. Hva er sannsynligheten i dette utvalget for å ha sykdommen?
Prevalens = 100 / 50000 = 1/500 = 0.002 = 0.2%
3. Hva er testens sensitivitet og spesifisitet, og hva betyr dette i ord?
Sensitivitet = P(P|S) = 95 / 100 = 95%
Spesifisitet = P(N|F) = 48902 / 49900 = 98%
*Har stått feil her tidligere (50000)
4. Hva er den positive prediktive verdi av testen? Hva betyr dette i ord, og hva betyr dette for testens praktiske verdi?
PPV = P(S|P) = 95 / 1093 ~= 0.087 = 8.7%
Når bare 8.7% av de positive utslagene er riktige er det nok ikke lurt å bruke testen som veiledende for pasientbehandling.
5. Finn også hva negativ prediktiv verdi av testen er.
NPV = P(F|N) = 48902 / 48907 ~= 0.999 = 99.9%
Ettersom PPV er lav, men NPV høy, er det rimelig å anta at testens styrke ligger i å minske utvalget ved å kjemme bort de som i allefall ikke er syke, altså de friske. Når det er gjort kan vi gjøre en annen diagnostisk test med høyere PPV, men kanskje lavere NPV.
6. Sett også opp positiv prediktiv verdi og negativ prediktiv verdi ved hjelp av Bayes regel.
PPV
P(S) = Prevalens = 0.002
P(P) = 1093 / 50000 ~= 0.022
P(P|S) = Sensitivitet ~= 0.95
P(S|P) = (P(S) / P(P)) * P(P|S) = (0.002 / 0.024) * 0.95 ~= 0.086 = 8.6%
NPV
P(F) = 49900 / 50000 = 0.998
P(N) = 48907 / 50000 ~= 0.978
P(N|F) = Spesifisitet ~= 0.978
P(F|N) = (P(F) / P(N)) * P(N|F) = (0.998 / 0.978) * 0.978 = 0.998 = 99.8%
7. Hvis vi i stedet tester utsatte risikogrupper, øker sannsynligheten for sykdommen til 5%. Testens sensitivitet og spesifisitet er den samme som du fant i pkt. 3 over. Hva skjer med positiv prediktiv verdi hvis vi ser på 50.000 personer med utsatt risiko for sykdommen?
PPV øker.
Vi ser på en annen type test, der sannsynligheten for å ha sykdommen i utsatte land er 10%. Sannsynligheten for at testen er positiv når man er smittet av sykdommen er 0.999 og sannsynligheten for at testen er negativ når man ikke er smittet er 0.99.
8. Hva er testens sensitivitet og spesifisitet?
Sensitivitet = P(P|S) = 0.999
Spesifisitet = P(N|F) = 0.99
9. Hva blir positiv prediktiv verdi? Bruk Bayes regel.
P(S) = Prevalens = 10%
PPV = Sensitivitet * Prevalens / (Sensitivitet * Prevalens + (1 – Spesifisitet) * (1 – Prevalens)) = 0.999 * 0.1 / (0.999 * 0.1 + (1 – 0.99) * (1 – 0.1)) ~= 0.92 = 92%
10. På verdensbasis er sannsynligheten for å ha sykdommen 1%. Hvis testens sensitivitet og spesifisitet er den samme, hva blir da positiv prediktiv verdi?
P(S) = 1%
PPV = Sensitivitet * Prevalens / (Sensitivitet * Prevalens + (1 – Spesifisitet) * (1 – Prevalens)) = 0.999 * 0.01 / (0.999 * 0.01 + (1 – 0.99) * (1 – 0.01)) ~= 0.50 = 50%
11. Ser du en sammenheng mellom prevalensen av sykdommen og positiv prediktiv verdi?
Ja.
ref
Foreleser: Morten Valberg
Ressurser
Oppgaver

 Det er klart at leger i løpet av karrieren vil komme i møte med pasienter som har dårlig kjennskap til statistikk og stor tiltro til tabloidmagasiner. Konklusjoner dratt fra statistiske data blir ofte mistolket og forenklet. I praksis er det svært tøft å finne koblinger som er 100% sikre. F.eks. var det en gruppe i Kina som drev forskning på om chili kunne forlenge livet. De samlet ~500 000 folk, spurte dem om spisevanene deres, og fulgte dem opp i 9 år. Resultatene tydet på at de som (hevdet at de) spiste chili 1-2 ganger i uka hadde i snitt en dødelighet som var ~10% lavere enn kontrollgruppen. De som spiste chili mer enn > 3 ganger i uka opplevde en reduksjon på 14%. Relativ risiko var satt til 0.86. Likevel er det ikke så enkelt som at man dermed kan fastslå med sikkerhet at chili øker forventet levealder. Studien kontrollerte for eksempel ikke for andre faktorer (salt-inntak, livsstil osv.). Derfor var konklusjonen at studien i likhet med andre epidemiologiske studier kun kunne etablere assosiasjoner.
Det er klart at leger i løpet av karrieren vil komme i møte med pasienter som har dårlig kjennskap til statistikk og stor tiltro til tabloidmagasiner. Konklusjoner dratt fra statistiske data blir ofte mistolket og forenklet. I praksis er det svært tøft å finne koblinger som er 100% sikre. F.eks. var det en gruppe i Kina som drev forskning på om chili kunne forlenge livet. De samlet ~500 000 folk, spurte dem om spisevanene deres, og fulgte dem opp i 9 år. Resultatene tydet på at de som (hevdet at de) spiste chili 1-2 ganger i uka hadde i snitt en dødelighet som var ~10% lavere enn kontrollgruppen. De som spiste chili mer enn > 3 ganger i uka opplevde en reduksjon på 14%. Relativ risiko var satt til 0.86. Likevel er det ikke så enkelt som at man dermed kan fastslå med sikkerhet at chili øker forventet levealder. Studien kontrollerte for eksempel ikke for andre faktorer (salt-inntak, livsstil osv.). Derfor var konklusjonen at studien i likhet med andre epidemiologiske studier kun kunne etablere assosiasjoner. Dersom man er stolt eier av Aalens bok, er det greit å vite at kapittel 7 (poissonfordeling), 12 (logistisk regresjon), 14 (Bayesiansk analyse) er utenfor pensum.
Dersom man er stolt eier av Aalens bok, er det greit å vite at kapittel 7 (poissonfordeling), 12 (logistisk regresjon), 14 (Bayesiansk analyse) er utenfor pensum.