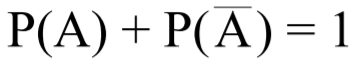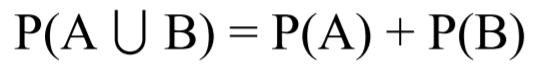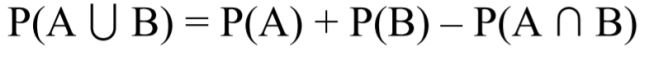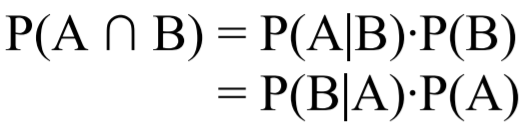Oppgave 9
1. Forklar hva vi mener med et konfidensintervall. Ta utgangspunkt i den binomiske situasjonen.
Om vi gjentar et forsøk mange ganger, vil et 95% konfidensintervall si at andelen konfidensintervall (basert på en estimert sannsynlighet) som inneholder den sanne populasjonsverdien p er 95%.
Binomisk situasjon: X ~ bin(n, p)
Konfidensintervall: p^ +- 1.96 * sqrt(p^(1-p^)/n) hvor sqrt(p^(1-p^)/n) er den estimerte standardfeilen.
Del 1
1. Gjør de beregningene som er nødvendige for å finne de feilmarginene som er oppgitt over.
Feilmarginene her vil si 1.96 * standardfeilene for et 95% konfidensintervall. Leser av partibarometer og får p^ = 0.297 for Ap og 0.250 for Høyre. Vi finner standardfeil ved Sp = sqrt(p^(1-p^)/n) hvor n er 721. Vi får Sp(Ap) ~= 0.017. 0.017 * 1.96 ~= 0.033. Sp(H) ~= 0.016. 0.016 * 1.96 ~= 0.032
2. Hva skal vi mene med øvre og nedre grense for partitilslutning? Gjør de beregningene som er nødvendig for å finne øvre og nedre grense for Arbeiderpartiet og Høyre. Hva synes du om overskriften til NRK: Dårlig måling for Støre: Ap under 30 prosent
Med øvre og nedre grense mener vi konfidensintervall. Formelen for et 95% konfidensintervall er p^ +- 1.96 * Sp. Vi får for Ap: 0.297 +- 0.033. For høyre får vi: 0.250 +- 0.032. Sannsynligheten for at den sanne oppslutningen for Ap er over 30% er nesten like stor som at den er under. Litt misvisende overskrift.
3. Kan vi bruke tilnærmingen til normalfordelingen i de beregningene vi gjør her? Hvor er det vi bruker den i våre beregninger?
Vi bruker antagelsen når vi regner ut feilmargin og konfidensintervall (øvre/nedre partigrense). Vi kan bruke tilnærmingen pg.a. sentralgrenseteoremet. np og nq er > 5.
Del 2
4. Gi en begrunnelse for at en skulle vente en binomisk fordeling med samme p hvis risikoen for spontanabort var den samme for hver kvinne.
- Kvinnene er uavhengig fra hverandre
- Vi kan måle om hendelsen spontanabort inntreffer
- Sannsynligheten for spontanabort er samme og konstant for hver kvinne
5. Hvilken andel av det totale antallet graviditeter har resultert i spontanabort?
p^ = ((28 + 14 + 15 + 24) = 81) / (70 * 4 = 280) ~= 0.29
6. Beregn et 95% konfidensintervall for andelen spontanaborter. Forklar med ord hva denne betyr. Kan vi bruke tilnærmingen til normalfordelingen her?
p^ ~= 0.29
Sp ~= 0.027
Feilmargin ~= 0.053
95% KI: (0.24, 0.34)
Vi tolker det slik at intervallet (0.24, 0.34) har en 95% for å inneholde den sanne populasjonsverdien p.
Vi kan bruke tilnærming pg.a. sentralgrenseteorem og np & nq > 5.
7. Hvis den binomiske sannsynligheten p settes lik denne andelen, beregn da de forventede antall kvinner med henholdsvis 0, 1, 2, 3 og 4 aborter. Sammenlign med den observerte fordelingen over. Diskuter eventuelle avvik.
(4 0): 0.254 * 70 = 17.78
(4 1): 0.415 * 70 = 29.05
(4 2): 0.254 * 70 = 17.78
(4 3): 0.069 * 70 = 4.83
(4 4): 0.007 * 70 = 0.49
Fra tabellen:
(4 0): 24
(4 1): 28
(4 2): 7
(4 3): 5
(4 4): 6
Vi ser at de forventede tallene vi får ikke stemmer så godt overens med tallene vi observerer. Dette kan tyde på at fordelingen vi har ikke er binomisk og at f.eks. p ikke er lik for alle kvinner.
Oppgave 10
1. Hva er sannsynligheten for at en (tilfeldig valgt) pasient med metabolsk syndrom har hjerte- og karsykdom. Finn et konfidensintervall for denne andelen.
p^ = 29/198 ~= 0.146
Sp ~= 0.025
95% KI: (0.097, 0.195)
2. Beregn differansen i andelen med hjerte- og karsykdom for dem med og uten metabolsk syndrom. Beregn også konfidensintervallet for differansen. Dette må du regne ut for hånd!
p^1 = 0.146
p^2 = 8/73 ~= 0.110
RD = 0.146 – 0.110 = 0.036
Regner ut konfidensintervall:
Finner felles standardfeil Sf = sqrt((p^1 * (1 – p^1) / n1) + (p^2 * (1 – p^2) / n2)) ~= 0.044
95% konfidensintervall er gitt ved: RD +- 1.96 * Sf
Vi får konfidensintervall (-0.05, 0.12).
3. Beregn relativ risiko (RR), med konfidensintervall.
RR = 0.146 / 0.110 ~= 1.33
95% konfidensintervall for RR er definert ved RR * e^(+- 1.96 * SRR) hvor SRR = sqrt(1/29 + 1/8 – 1/198 – 1/73) ~= 0.375. Da får vi konfidensintervall (0.64, 2.77).
4. Beregn også odds ratio (OR), med konfidensintervall.
OR = (29/169) / (8/65) ~= 1.39
95% konfidensintervall for OR er definert ved OR * e^(+- 1.96 * SOR) hvor SOR = sqrt(1/29 + 1/8 + 1/169 + 1/65) ~= 0.425. Da får vi konfidensintervall (0.60, 3.20).
5. Du har i pkt. 2, 3 og 4 beregnet tre alternative mål for effekten som metabolsk syndrom har på hjerte- og karsykdom. Hvilket av disse ville du bruke hvis du skal presentere dette for en gruppe lekfolk?
Alle effektmålene har egne styrker. I denne sammenhengen ville jeg valgt RR eller RD da disse er lettere å forstå. Vi får at en pasient med metabolsk syndrom er ~33% (1.33) mer eksponert for hjerte- og karsykdom. RD forteller oss at den reelle forskjellen er ~3.6%.
6. Sett opp nullhypotesen for å studere om andelene med hjerte- og karsykdom er like for
dem med og uten metabolsk syndrom. Test nullhypotesen. Hvilken konklusjon finner
du?
Vi kan bruke Y-test og Chi-kvadrat-test.
Y-test:
Setter α-nivå = 0.05
H0: p1 = p2
HA: p1 != p2
p^1 ~= 0.146
p^2 ~= 0.110
Finner z-skår, altså Y = (p^1 – p^2) / sqrt(((1/n1)+(1/n2))*p-(1-p-)) hvor p-, den gjennomsnittlige p, = (x1 + x2) / (n1 + n2). Vi får da Y ~= 0.77 som gir i tabellen 0.7794. P-verdi blir da 2*(1 – 0.7794) ~= 0.44. Dette er mye større enn 0.05. Vi kan ikke forkaste H0.
Chi-kvadrat-test:
H0: p1 = p2
HA: p1 != p2
Andel med metabolsk syndrom: 198/271 ~= 0.73
Forventet andel med metabolsk syndrom med hjerte- og karsykdom: 37*0.73 = 27.01
Forventet andel med metabolsk syndrom uten hjerte- og karsykdom: 234*0.73 = 170.82
Andel uten metabolsk syndrom: 73/271 ~= 0.27
Forventet andel uten metabolsk syndrom med hjerte- og karsykdom: 37*0.27 = 9.99
Forventet andel uten metabolsk syndrom med hjerte- og karsykdom: 234*0.27 = 63.18
Vi regner ut teststørrelse X^2:
X^2 = (29 – 27.01)^2 / 27.01 + (169 – 170.82)^2 / 170.82 + (8 – 9.99)^2 / 9.99 + (65 – 63.18)^2 / 63.18 ~= 0.61
Antall frihetsgrader: (kolonner – 1) * (rader – 1) = 1
For α-nivå 0.05 har vi en verdi 3.84. Fordi teststørrelsen vi fant er mye mindre enn 3.84, kan vi ikke forkaste H0.
Oppgave 11
1. Bruk tabellen til å undersøke om andelen med hjerte- og karsykdom avhenger av om personen er overvektig eller ikke. Sett opp en nullhypotese og test den.
Vi kan bruke Y-test og Chi-kvadrat-test.
Y-test:
Setter α-nivå = 0.05
H0: p1 = p2
HA: p1 != p2
p^1 ~= 0.19
p^2 ~= 0.060
Finner z-skår, altså Y = (p^1 – p^2) / sqrt(((1/n1)+(1/n2))*p-(1-p-)) hvor p-, den gjennomsnittlige p, = (x1 + x2) / (n1 + n2). Vi får da Y ~= 6.32 som gir i tabellen > 0.9998. P-verdi blir da < 2*(1 – 0.9998) ~= 0.0004. Dette er mye mindre enn 0.05. Vi kan med god sikkerhet forkaste H0.
Chi-kvadrat-test:
H0: p1 = p2
HA: p1 != p2
Andel med overvekt: 312/994 ~= 0.31
Forventet andel med overvekt med hjerte- og karsykdom: 100*0.31 = 31
Forventet andel med overvekt uten hjerte- og karsykdom: 894*0.31 = 277.14
Andel uten overvekt: 682/994 ~= 0.69
Forventet andel uten overvekt med hjerte- og karsykdom: 100*0.69 = 69
Forventet andel uten overvekt med hjerte- og karsykdom: 894*0.69 = 616.86
Vi regner ut teststørrelse X^2:
X^2 = (60 – 31 )^2 / 31 + (40 – 69)^2 / 69 + (252 – 277.14)^2 / 277.14 + (642 – 616.86)^2 / 616.86 ~= 42.62
Antall frihetsgrader: (kolonner – 1) * (rader – 1) = 1
For α-nivå 0.05 har vi en verdi 3.84. Fordi teststørrelsen vi fant er mye større enn 3.84, kan vi med god sikkerhet forkaste H0.
2. Bruk differansen i andelen med hjerte- og karsykdom som effektmål for effekten av overvekt på hjerte- og karsykdom. Finn et estimat for effekten og lag et konfidensintervall (for hånd!).
p^1 ~= 0.19
p^2 ~= 0.060
RD = 0.19 – 0.060 = 0.13
Regner ut konfidensintervall:
Finner felles standardfeil Sf = sqrt((p^1 * (1 – p^1) / n1) + (p^2 * (1 – p^2) / n2)) ~= 0.024
95% konfidensintervall er gitt ved: RD +- 1.96 * Sf
Vi får konfidensintervall (0.083, 0.18).
3. Bruk relativ risiko som effektmål. Beregn den og finn et konfidensintervall for den.
RR = 0.19 / 0.060 ~= 3.17
95% konfidensintervall for RR er definert ved RR * e^(+- 1.96 * SRR) hvor SRR = sqrt(1/60 + 1/40 – 1/312 – 1/682) ~= 0.19. Da får vi konfidensintervall (2.18, 4.60).
4. Bruk odds ratio som effektmål, beregn den og finn konfidensintervallet.
OR = (60/252) / (40/642) ~= 3.82
95% konfidensintervall for OR er definert ved OR * e^(+- 1.96 * SOR) hvor SOR = sqrt(1/60 + 1/40 + 1/252 + 1/642) ~= 0.22. Da får vi konfidensintervall (2.48, 5.88).
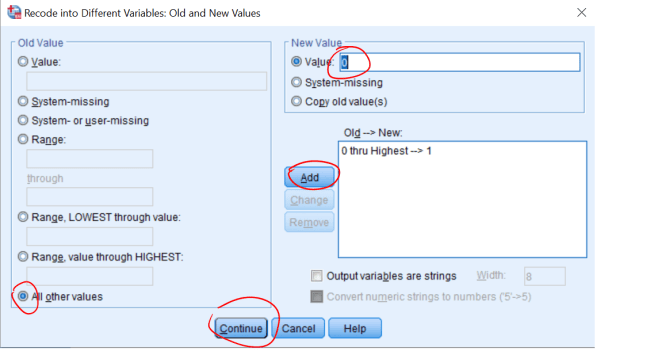
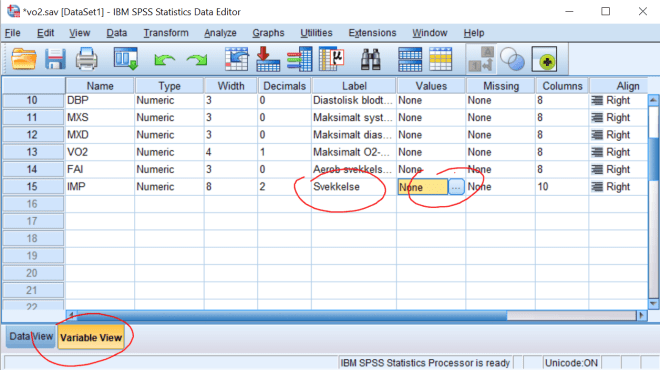
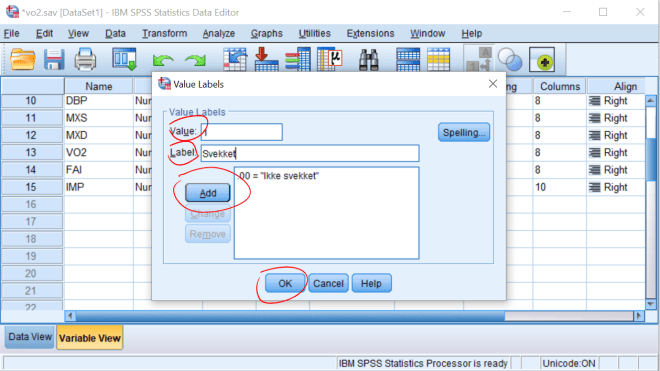
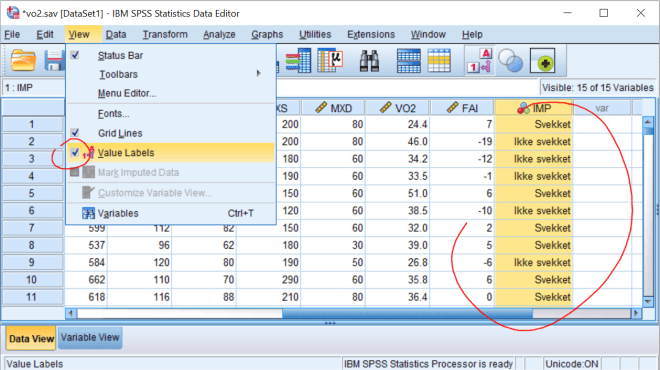
5. Les inn tabellen over i SPSS. Lag variabelnavn, variabel labels og value labels og
presenter selve tabellen.
Kommer senere
6. Beregn RR, OR med tilhørende konfidensintervall ved å bruke SPSS.
Kommer senere
7. Hvordan vil du presentere sammenhengen mellom overvekt og hjerte- og karsykdom, og hvordan vil du konkludere om sammenhengen mellom overvekt og hjerte- og karsykdom?
Alle effektmålene har egne styrker. I denne sammenhengen ville jeg valgt RR eller RD da disse er lettere å forstå. Vi får at en pasient med overvekt er ~317% (3.17) mer eksponert for hjerte- og karsykdom. RD forteller oss at den reelle forskjellen er ~13%. Vi ser at om H0 for RR = 1 og RD = 0, er ingen av disse inkludert i deres tilsvarende 95% konfidensintervall. Vi kan si med 95% sikkerhet at det er en betydelig sammenheng mellom overvekt og økt forekomst av hjerte- og karsykdom.
Foreleser: Simon Lergenmuller
Ressurser
Oppgaver





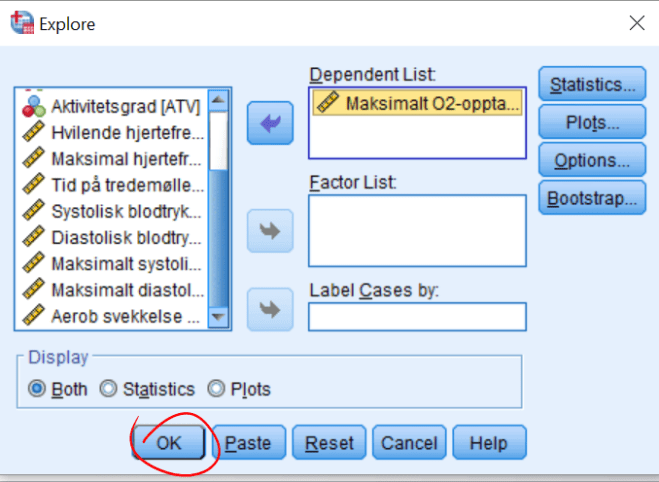

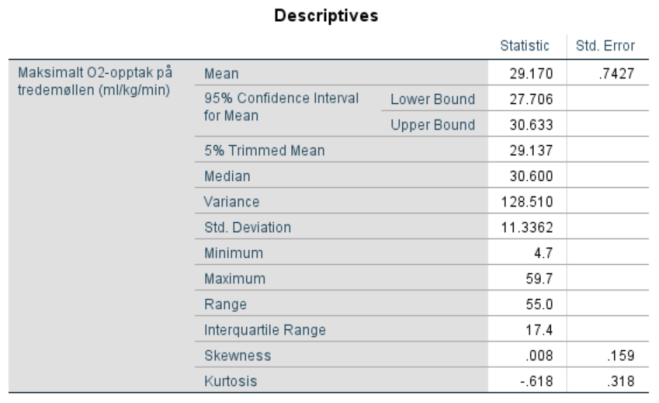
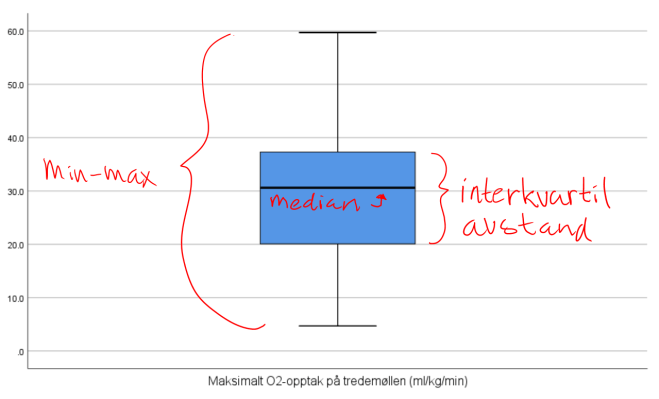

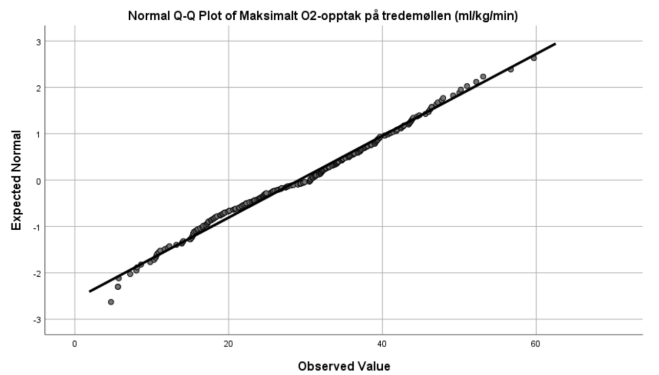
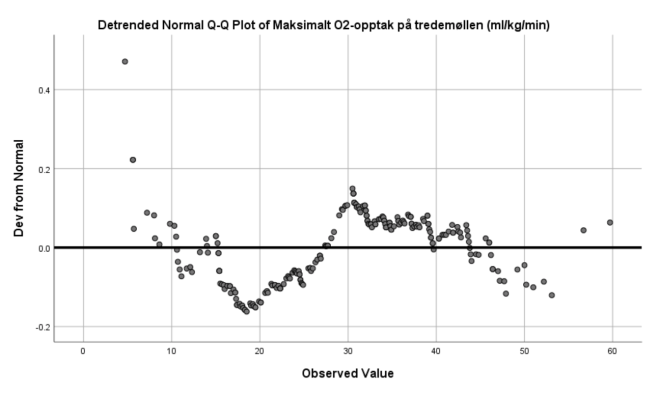
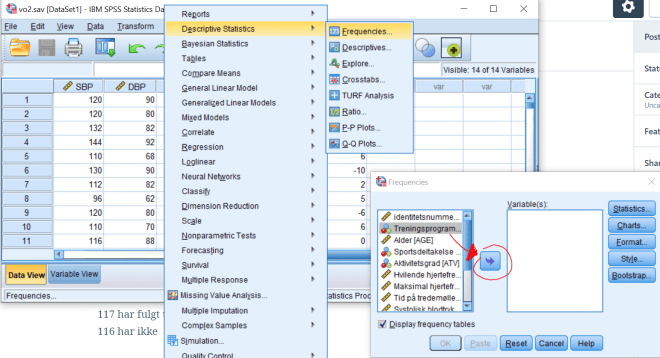
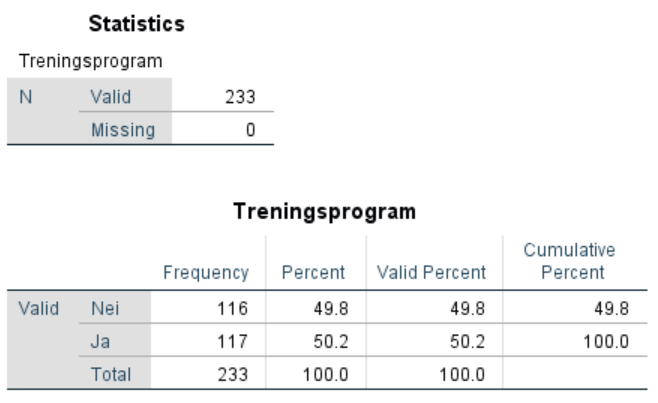

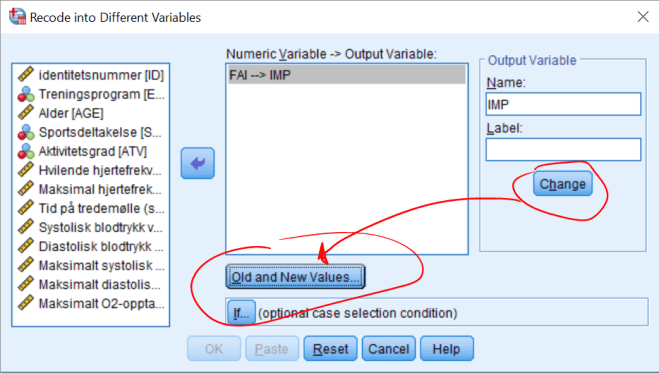
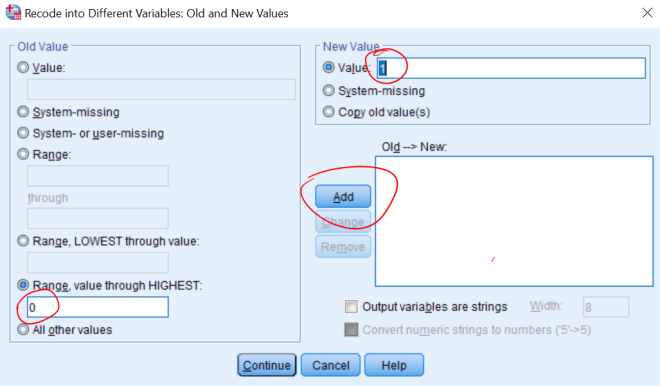
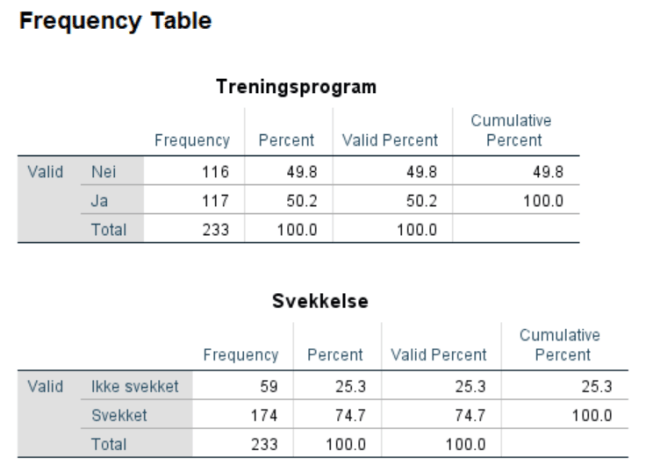
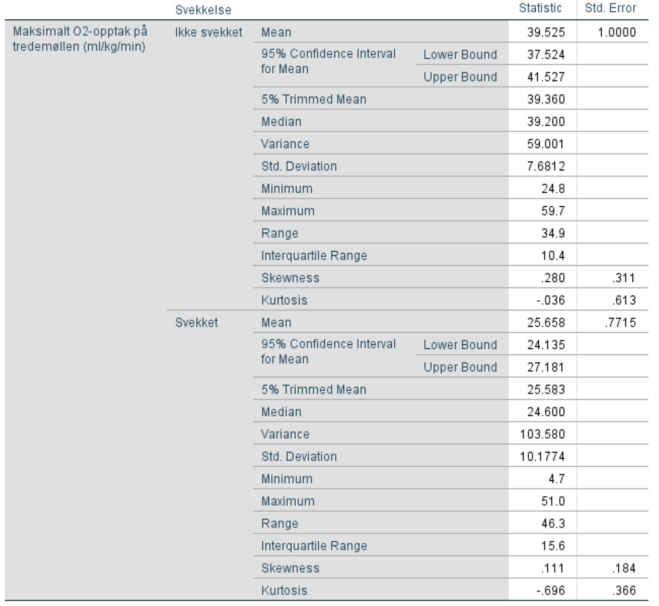
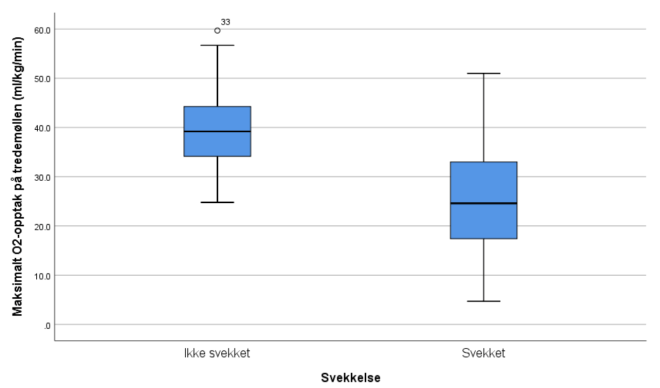

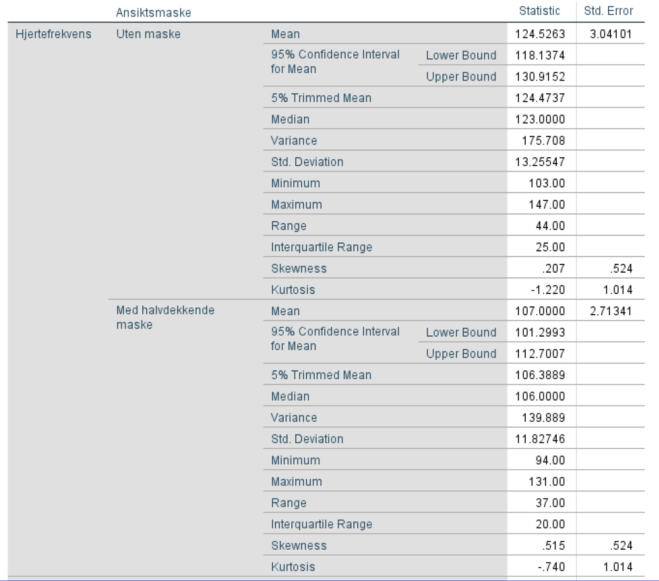
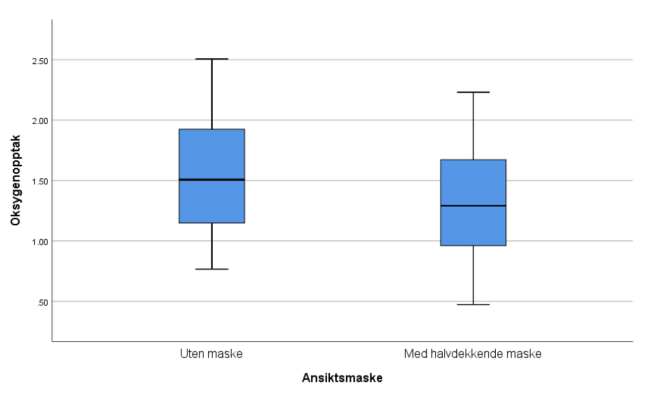
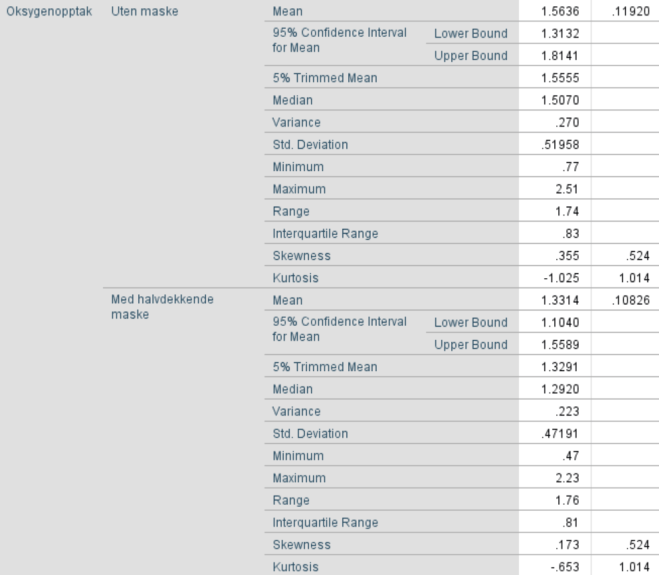 4. Lag boksplott for VO2 og HR for personer med og uten bruk av ansiktsmaske. Forklar hva du finner. Er fordelingen til disse to variablene symmetriske?
4. Lag boksplott for VO2 og HR for personer med og uten bruk av ansiktsmaske. Forklar hva du finner. Er fordelingen til disse to variablene symmetriske?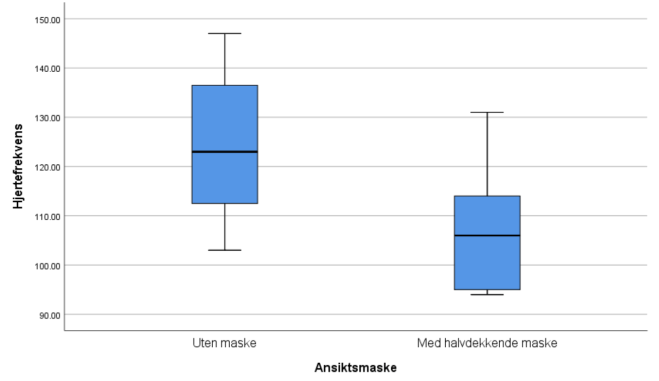

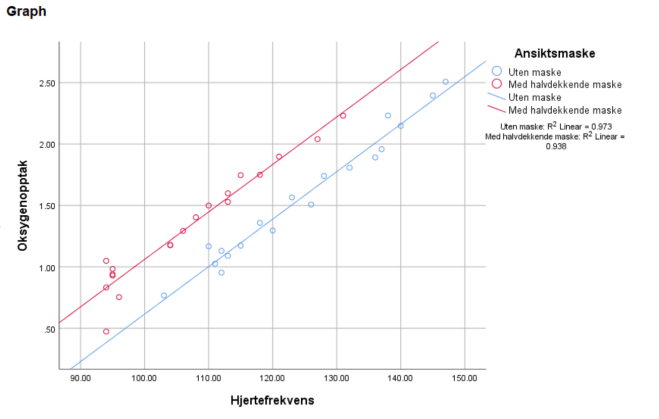 Det at grafene (regresjonslinjene) er tilnærmet parallelle betyr at veksten (proporsjonalitetskonstanten a i y=ax+b) er ~lik. Grunnen til at grafene er forskjøvet er fordi oksygenopptaket er generelt lavere med maske på (gir mening i praksis!).
Det at grafene (regresjonslinjene) er tilnærmet parallelle betyr at veksten (proporsjonalitetskonstanten a i y=ax+b) er ~lik. Grunnen til at grafene er forskjøvet er fordi oksygenopptaket er generelt lavere med maske på (gir mening i praksis!).
 })
})